回顧一下LDA 中,生成文檔的過程如下:
LDA參數關係示意圖
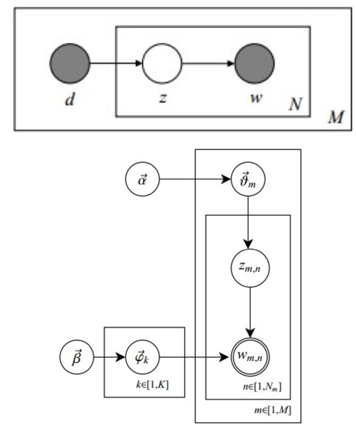
上圖表示生成第m篇文檔的時候,先從抽取了一個doc-topic骰子, 然後投擲這個骰子生成了文檔中第n個詞的topic編號, 這個過程表示,從K個topic-word骰子中,挑選編號為的骰子進行投擲,然後生成詞彙;
參考練習
資料下載自kaggle的新聞範例資料
https://www.kaggle.com/therohk/million-headlines/data
import pandas as pd
data = pd.read_csv('abcnews-date-text.csv', error_bad_lines=False);
data_text = data[['headline_text']]
data_text['index'] = data_text.index
documents = data_text
1048575
資料前處理:包含斷詞、去除stop word、詞原型還原、保留詞莖
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
import numpy as np
import nltk
nltk.download('wordnet')
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
def preprocess(text):
result = []
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return result
建立詞頻表bow_corpus
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
bow_corpus[4310]
印出
[(76, 1), (112, 1), (483, 1), (3998, 1)]
預覽建立的bow_corpus
bow_doc_4310 = bow_corpus[4310]
for i in range(len(bow_doc_4310)):
print("Word {} ("{}") appears {} time.".format(bow_doc_4310[i][0],
dictionary[bow_doc_4310[i][0]],
bow_doc_4310[i][1]))
印出
Word 76 (“bushfir”) appears 1 time.
Word 112 (“help”) appears 1 time.
Word 483 (“rain”) appears 1 time.
Word 3998 (“dampen”) appears 1 time.
做TF-IDF處理,把經常出現的詞重要性降低
from gensim import corpora, models
tfidf = models.TfidfModel(bow_corpus)
corpus_tfidf = tfidf[bow_corpus]
from pprint import pprint
for doc in corpus_tfidf:
pprint(doc)
break
瀏覽每一篇文章的TF-IDF score
[(0, 0.5907943557842693),
(1, 0.3900924708457926),
(2, 0.49514546614015836),
(3, 0.5036078441840635)]
建立LDA模型
Genism套件中內建lad_model
lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics=10, id2word=dictionary, passes=2, workers=2)
針對每一個topic(關鍵字標籤),顯示所有相關的word以及權重
for idx, topic in lda_model.print_topics(-1):
print('Topic: {} \nWords: {}'.format(idx, topic))
印出
顯示10個topic下,最重要的10個關鍵字,以及它們的權重
參考來源
Topic Model的分類和設計原則
https://read01.com/zh-tw/oO2LoJ.html#.W97UyGQzYk8
一文詳解LDA主題模型
https://read01.com/gg5PJKA.html#.W-AwT2QzbzU
Topic Modeling and Latent Dirichlet Allocation (LDA) in Python
https://towardsdatascience.com/topic-modeling-and-latent-dirichlet-allocation-in-python-9bf156893c24


 iThome鐵人賽
iThome鐵人賽